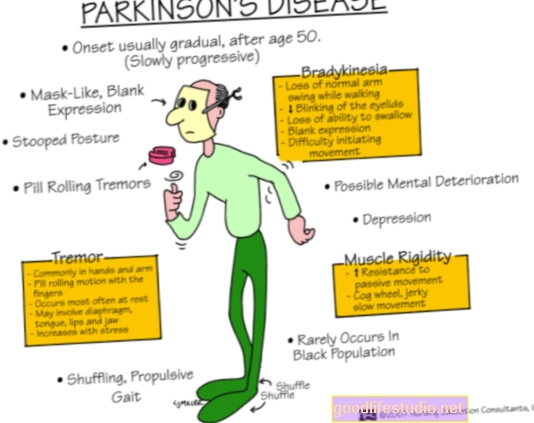
Имагинг мозга, машинско учење може помоћи у предвиђању ризика од менталних болести
Истраживачи комбинују податке о сликању мозга и суперкомпјутере како би идентификовали обрасце у подацима за неуросликовање који могу помоћи у предвиђању ризика за менталне поремећаје попут депресије или деменције.
Депресија сваке године погађа више од 15 милиона одраслих Американаца, или око 6,7 одсто америчке популације. Водећи је узрок инвалидитета за људе између 15 и 44 године.
Доктор Давид Сцхниер, когнитивни неуронаучник и професор психологије са Универзитета Тексас у Аустину, рекао је да способност предвиђања ризика од менталних болести није једноставна ствар.
Користи суперкомпјутер за обуку алгоритма за машинско учење који може идентификовати заједничке карактеристике међу стотинама пацијената помоћу скенирања мозга са магнетном резонанцом (МРИ), геномских података и других релевантних фактора, како би пружио тачне предвиђања ризика за оне који имају депресију и анксиозност. .
Истраживачи су дуго проучавали менталне поремећаје испитивањем везе између функције мозга и структуре у подацима о неуросликавању.
„Једна потешкоћа са тим делом је што је пре свега описан. Можда се чини да се мождане мреже разликују између две групе, али нам не говори о томе који обрасци заправо предвиђају у коју ћете групу пасти “, рекао је Сцхниер.
„Тражимо дијагностичке мере које предвиђају исходе попут рањивости на депресију или деменцију.“
2017. године, Сцхниер је, радећи са истраживачима са различитих универзитета, довршио анализу студије доказа о концепту која је користила приступ машинском учењу за класификацију појединаца са великим депресивним поремећајем са приближно 75 процената тачности.
Међу истражитељима су били и др. Петер Цласен (Медицински факултет Универзитета у Вашингтону), Цхристопхер Гонзалез (Университи оф Цалифорниа, Сан Диего) и Цхристопхер Бееверс (Университи оф Текас, Аустин).
Машинско учење је потпоље рачунарске науке које укључује изградњу алгоритама који могу „учити“ градећи модел на основу узорака података, а затим независно предвиђати нове податке.
Истраживачи су пружили низ примера обуке, од којих је сваки означен да припада или здравим особама или онима којима је дијагностикована депресија. Сцхниер и његов тим означили су значајне податке у својим подацима, а ови примери су коришћени за обуку система.
Рачунар је затим скенирао податке, пронашао суптилне везе између различитих делова и изградио модел који додељује нове примере једној или другој категорији.
У студији је Сцхниер анализирао податке о мозгу од 52 учесника који су депресијом тражили лечење и 45 учесника који су контролисали здравље. Да би упоредили групе, упоредили су подскуп депресивних учесника са здравим појединцима на основу старости и пола, повећавајући узорак на 50.
Учесници су добили МРИ скенирање дифузног тензора (ДТИ), које означава молекуле воде да би се утврдило у којој мери се ти молекули временски микроскопски дифундирају у мозгу.
Истражитељи су упоредили резултујућа мерења између две групе и утврдили статистички значајне разлике. Потом су сведене податке свели на подскуп који је најрелевантнији за класификацију и извршили су класификацију и предвиђање користећи приступ машинског учења.
„Уносимо целокупне податке о мозгу или подскупине и предвиђамо класификације болести или било које потенцијалне мере понашања, попут мера пристрасности негативних информација“, каже он.
Студија је открила да подаци о мозгу могу тачно класификовати депресивне или рањиве особе у односу на здраву контролу. Такође је показало да се предиктивне информације дистрибуирају кроз мождане мреже, а не да су високо локализоване.
„Не само да учимо да можемо класификовати депресивне наспрам недепресивних људи користећи ДТИ податке, већ сазнајемо и нешто о томе како је депресија представљена у мозгу“, рекао је Бееверс, професор психологије и директор Института за ментално здравље Истраживање на Универзитету у Тексасу, у Аустину.
„Уместо да покушавамо да пронађемо подручје које је поремећено депресијом, ми сазнајемо да промене на бројним мрежама доприносе класификацији депресије.“
Обим и сложеност проблема захтевају приступ машинском учењу. Сваки мозак је представљен са отприлике 175.000 воксела и откривање сложеног односа између тако великог броја компонената гледањем у скенирање је практично немогуће.
Из тог разлога, тим користи машинско учење за аутоматизацију процеса откривања.
„Ово је талас будућности“, каже Сцхниер.„Све већи број чланака и презентација видимо на конференцији о примени машинског учења за решавање тешких проблема у неуронауци.“
Резултати обећавају, али још увек нису довољно јасни да би се могли користити као клиничка метрика. Међутим, Сцхниер верује да додавањем више података, не само МРИ скенирања, већ и геномике и других класификатора, систем може учинити много боље.
„Једна од благодати машинског учења у поређењу са традиционалнијим приступима је да би машинско учење требало да повећа вероватноћу да се оно што примећујемо у нашој студији примени на нове и независне скупове података. Односно, требало би да генерализује нове податке “, рекао је Бееверс.
„Ово је критично питање које ћемо заиста радо тестирати у будућим студијама.“
Извор: Универзитет Тексас у Аустину, Тексашки напредни рачунски центар